Decoding the Civil War: Phase 2, Two Work Flows, Your Choice
After a year of hard work by our volunteers on Decoding the Civil War, Phase 1, we are about ready to launch Phase 2, the marking of metadata within specific telegrams. There are two work flows to this task. The first work flow, Code Words, is marking the arbitraries, or code words, for those messages in code. These coded telegrams will then be fed into Phase 3, the final decoding of the telegrams. Having the marked arbitraries should make the process of decoding much faster, possibly aided by computer algorithms.
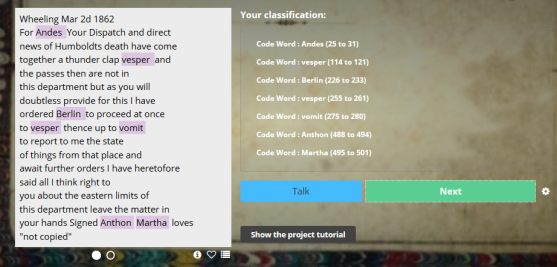
Example of highlighted code words (arbitraries).
The second work flow, Metadata, is a little more ambitious and complex, as we are asking our volunteers to work with individual telegrams, identifying specific metadata such as the sender, recipient, date sent, time received, etc. We are asking for metadata for a total of 10 fields; most telegrams have only a few; rarely do they have all 10. What we wish to accomplish is a way to provide simple metadata that will enable researchers to find all the telegrams to, say, Secretary of War Edwin M. Stanton, no matter whether it is in Ledger 2, or 6, or 22.
But did not Phase 1 enable full-text searching? Yes it did, and it is wonderful, but the transcriptions are accurate to the text as written in the ledger. Keeping with Stanton, if you typed in “Stanton” in the search box, you would get those pages where “Stanton” matches the search. But what if the telegram begins or ends with “EMS” or “Stantin” or “the Secretary of War”? The full-text search would ignore those pages. Furthermore, such a search looks at the whole message and returns results for any mention of “Stanton,” including other people named Stanton or places named Stanton. What if you want to look for Stanton only as the recipient? A search in a specific metadata field for “recipient” would enable that search and give you the correct results.
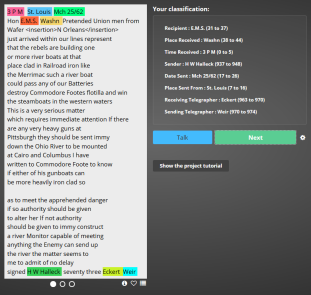
Example of highlighted metadata fields.
To aid in that search we will take the metadata tagged by the volunteers in Phase 2 and standardize the terms. So, continuing with Stanton, if the recipient is “EMS” and it is tagged as a sender or recipient, we will be able to take the consensus term and edit it to the standardized form of “Stanton, Edwin M. (Edwin McMasters), 1814-1869.” Once all the telegrams are tagged and the fields edited, if you do a specific search for “Recipient” as “Stanton, Edwin M. (Edwin McMasters), 1814-1869.” you will only get those telegrams to Stanton, not from or about him, and you will have those whether they are sent to him as “EMS,” “Stanton,” or “Stantin.”
The tagging of individual telegrams in the Phase 2 Metadata workflow will eventually enable specific searches to be done across the almost 16,000 telegrams. It will enable users to look for individuals or places or dates in specific fields. And the tagging of code words (arbitraries) in the Code Word work flow will help round out this project with the final decoding of encoded telegrams. An incredibly useful archive has been made available in Phase 1 of Decoding the Civil War. Help us leverage and categorize that hard-earned knowledge in Phase 2 to aid in the discovery of the American Civil War.
The Beta Test site for Phase 2 is here. The original site can be seen here.
So What Does a Consensus Transcription Look Like, Exactly?
Providing an accurate transcription of the Thomas T. Eckert Papers is one of the primary goals of Decoding the Civil War. It’s why we applied to the National Historical Publications and Records Commission (NHPRC) for a grant, and it’s why our thousands of volunteers have put so much time and effort into this project. With more than 4,000 subjects, or pages, now retired, the folks at at Zooniverse have begun the process of establishing the consensus transcriptions, and we are excited and pleased with the results.
Each page, whether in the telegram ledgers or the codebooks, is seen by multiple people. The pages that have been “retired” are those that have been seen and classified by a sufficient number of people. To find the consensus transcription, an algorithm is run that compares every word and finds the most frequently used one. This doesn’t guarantee that the transcription is accurate, and we are allowing for corrections in the future, but it gives us a version of the text that most people agree on.
Let’s look, for example, at this telegram from the top of page 8, ledger 1:

The consensus lines and box are fairly straightforward – they were made by averaging the locations drawn by everyone who classified this page. As you can see, there are some quirks, such as the weirdly short top line, which we have seen consistently throughout the reviewed data: some people underlined the entire top line, while others split it into two smaller lines. The lack of underlining with the second line of the telegram is a bit harder to parse out, but most people transcribed “sent”, so the effect on the transcription was minimal. The box comes from that last step of “boxing” the telegram. It will prove very useful in Phase 2 when we parse out individual telegrams, as we have done in the example above.
So, what does the consensus transcription look like for this telegram?! Without further ado….
Louisville 4′ Recd Feb Feb 4 ’62
Col Colburn asst adjt General Ocean
they had better not be sent
I may want them soon if
they are ready for service Alvord
Huzzah! With the exception of that duplicated “Feb”, this seems to be spot on.
Here’s a closer look at the breakdown of the responses:

The numbers underneath each word indicate the number of people who transcribed it that way. The Zooniverse team uses these numbers to calculate the reliability of each line and each page. This message comes from a page with a reliability value of .8658, an excellent value on the scale from .0 to 1.0. We are currently working on determining what is an acceptable base level, or floor, of reliability. Pages whose reliability is lower than that base level will have to be reviewed further, or placed back into the transcription queue.
Once we have an acceptably reliable consensus transcription for a ledger, we will load that transcription into the Huntington Digital Library, so that researchers can start using the materials in a keyword-searchable form. At the same time we will be loading individual telegrams into Phase 2 of Decoding the Civil War, in which volunteers will tag metadata such as sender, recipient, times sent and received, and more. The fruits of the volunteer labor of “boxing” the telegram come into play here with the consensus box helping us determine the correct location on the page of the telegram.
We are incredibly excited about our progress so far, and can’t wait to share more of our findings in the near future!
